Database Types for Agent-First Systems
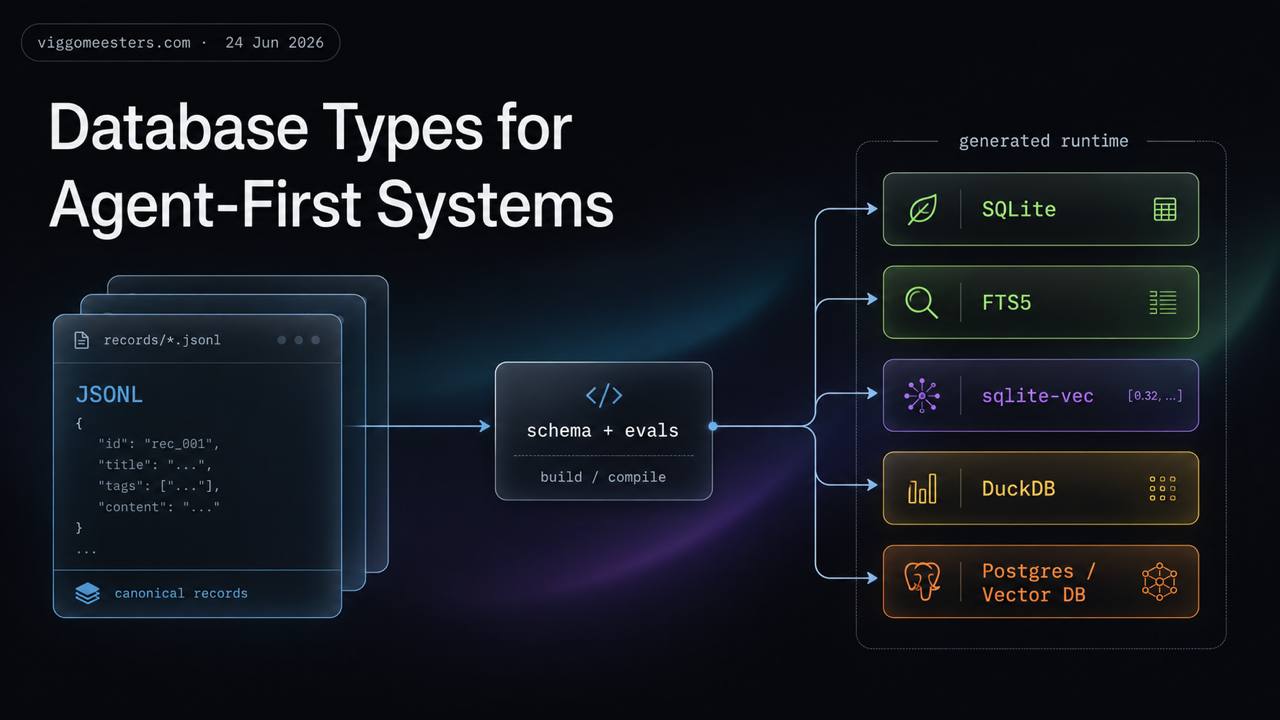
Once JSONL is the canonical record layer, the next question is not “which database should replace it?” It is which generated runtime surface should serve each job: exact lookup, semantic search, analytics, application state, or hosted scale.
1The rule
In JSONL Is the Agent-First Data Structure, the core claim is simple: for agent-first knowledge systems, the canonical source should be atomic JSONL records validated by schema and tested by evals.
That does not mean databases are unimportant. It means databases should usually be compiled runtime surfaces. The source stays transparent and reviewable; the runtime becomes fast and queryable.
Use JSONL for canonical facts. Generate SQLite, FTS, vector indexes, DuckDB files, Postgres tables, or hosted vector stores from it depending on the job.
2The decision matrix
| Tool | Best job | Do not use it as |
|---|---|---|
JSONL | Canonical atomic records, Git review, schema validation, streaming ingest. | A low-latency query engine. |
SQLite | Local runtime database, filters, joins, portable build artifact, small app state. | The canonical public corpus when diffs and merges matter. |
SQLite FTS5 | Exact and lexical search: SAP codes, table names, transaction IDs, keywords, BM25. | Semantic retrieval for vague natural-language questions. |
sqlite-vec | Local semantic vector search inside the same SQLite artifact. | A hosted multi-tenant vector platform. |
DuckDB | Columnar analytics, coverage audits, CSV/Parquet work, bulk quality reports. | The primary local RAG runtime for a small agent corpus. |
DuckDB VSS | Analytical vector experiments and batch similarity checks near tabular data. | The default replacement for SQLite + FTS in an agent lookup layer. |
Qdrant / Pinecone | Service-style vector search, remote API access, larger deployments, ops-owned retrieval service. | The first step for a local personal or repo-contained context system. |
Postgres | Application state, concurrency, users, permissions, transactions, production APIs. | A reviewable source file format. |
Turso / libSQL | SQLite-like distribution, edge/local sync, app-facing read replicas. | A reason to make opaque generated state canonical. |
3The local runtime stack
For a local agent corpus, the sweet spot is often boring:
SQLite gives the agent filters and joins. FTS5 gives exact lookup. sqlite-vec adds semantic search without introducing a separate server. Together they feel close to a local Pinecone, but with a single rebuildable file and no cloud dependency.
The important detail is hybrid retrieval. For SAP-like domains, exact tokens matter. A query for IE03, EQUI, DD03VT, or a migration object should not disappear behind a fuzzy embedding match. The query layer should filter first, score exact terms strongly, then use vectors for natural-language recall.
4What this means for SAP Agent Context
For SAP Agent Context, I would keep the canonical layer as:
records/apps.jsonl
records/tables.jsonl
records/fields.jsonl
records/workflows.jsonl
records/roles.jsonl
records/claims.jsonl
records/sources.jsonl
records/relations.jsonl
schema/*.schema.jsonThen generate the runtime layer:
build/context.sqlite
items
claims
sources
relations
item_fts
claim_fts
vec_items
vec_claims
build/vector-corpus.jsonl
build/embeddings-cache.jsonlClaims matter here. A useful SAP answer should not only retrieve an item. It should retrieve the item, the claim, and the evidence or source pointer that supports it. That pushes the schema beyond “one document chunk with an embedding” toward citeable records.
5Wrong turns to avoid
- Making SQLite canonical too early. You get speed, but lose clean diffs, simple review, and mergeable records.
- Using vectors for exact identifiers. Embeddings are good at meaning, bad at treating
ME21NandME22Nas operationally different. - Choosing DuckDB because it sounds more serious. DuckDB is excellent for analytics. It is not automatically the best embedded retrieval database.
- Starting with Pinecone for a local repo. A hosted vector DB may be right later. It is rarely the first move when the corpus lives in Git.
- Forgetting evals. Retrieval quality is a contract. Store fixtures for expected hits, confusing misses, and citation coverage.
6My default architecture
For most repo-contained agent context systems, I would start with this:
JSONL + JSON Schema as canonical truth. SQLite + FTS5 + sqlite-vec as the local runtime. DuckDB as an optional analytics companion. Postgres/Turso/Qdrant only when the product grows into application state, sync, or service-scale retrieval.
That keeps the system small enough to clone, inspect, validate, rebuild, and run on one machine. It also keeps the door open: the same JSONL records can later compile into DuckDB, Postgres, Turso, Qdrant, or Pinecone if the job actually demands it.
The architecture is not anti-database. It is pro-boundary: canonical truth in reviewable records, generated databases for runtime jobs.